
v2.54
6 Jan 2023
Download
(Windows, Linux, OSX)
Contrib
(GUIs; Native Kindle PDF Viewer)
Help
(with videos)
FAQ
 Forum Forum 
Wiki
History
Source
Arch
Linux
PDF
Conversion
Tips
Linux Install
Mac Install
|
OVERVIEW
K2pdfopt optimizes PDF/DJVU files for mobile e-readers (e.g. the Kindle) and smartphones.
It works well on multi-column PDF/DJVU files and can re-flow text even on scanned PDF files.
It can also be used as a general PDF copying/cropping/re-sizing/OCR-ing manipulation tool.
It can generate native or bitmapped PDF output, with an optional OCR layer. There are
downloads for MS Windows, Mac OSX, and Linux. The MS Windows
version has an integrated GUI. K2pdfopt is open source.
Note to MS Word users: While I still suggest you try out k2pdfopt, if you truly
want to convert your PDF to an e-book format like epub or mobi, you might want to check
my most recommended solution for this on my PDF Conversion Tips page.
Here's a quick example of what k2pdfopt can do (click on the images below to get the PDF files):
IT TURNS THIS . . .
(8.5 x 11 PDF or DJVU file) |
 |
. . . INTO THIS.

(6-inch reader screen) |
|
. . . OR THIS.

(4-inch smartphone screen)
|
|
MS Windows integrated GUI front-end
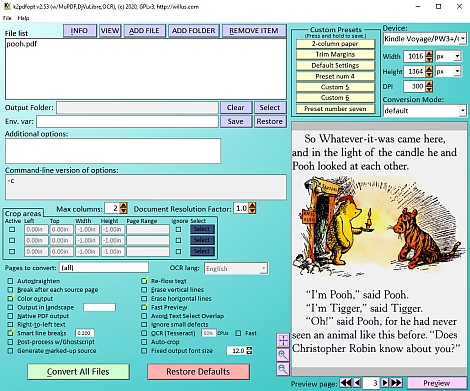
|
Unsolicited comments from k2pdfopt users (refresh the page to change the comments):
[an error occurred while processing this directive]
|
LATEST NEWS
| 18 Feb 2023 |
|
I've added to my blog some benchmarking / testing that I did when
I was building k2pdfopt v2.54: a
gcc v12 / k2pdfopt benchmark and an updated
tesseract accuracy study.
|
| 18 Feb 2023 |
|
The download page for some time was not correctly showing
a link to the Win64 v2.54 version. I'm not sure what caused it. It has been fixed.
|
| 6 Jan 2023 |
|
K2pdfopt v2.54 released.
There is no update to the k2pdfopt source code in this release--only to the
libraries--notably Tesseract v5.3.0 which improves the OCR speed. This
version is also compiled with the latest gcc compiler, v12.2.
See details in the k2pdfopt version history.
|
| 6 Mar 2022 |
|
I did some experimenting with Tesseract (OCR) v5.1 today. I compiled
it and benchmarked it with a standard test I have. It uses the same training files and
has identical accuracy to Tesseract v4.1, but uses a new 32-bit floating point calculation
technique, that, interestingly, is 30% faster on the "best" english training file but
40% slower than Tesseract 4.1 on the "fast" english training file (on a Core i9-9900 CPU).
The optimum character height of a capital letter is between 25 and 35 pixels for the best
accuracy for both Tesseract v4.1 and v5.1.
|
| 4 Mar 2022 |
|
I've added a Linux Aarch64 binary to my download page which
I cross-compiled on a Debian 10 virtual linux box on my Windows PC. I'd be curious
if anybody can give me feedback whether it works or not. I had a user request a binary
for their Pinephone, so I'm hoping this will work.
|
| 12 Jul 2021 |
|
I've re-worked my download page a bit to try and make it smarter
about forcing a fresh load every time as opposed to the browser pulling it up from
an internal cache, which can cause problems with expired capcha values. If you get an
expired capcha, try refreshing
the download page manually in your browser (click the refresh button).
|
| 23 Jan 2021 |
|
Apple OS/X M1 Arm-64 version of
k2pdfopt v2.53 released. See the download page. This version will only run
on the latest Macs with the M1 chip, which is a very impressive performer. See the table
below comparing k2pdfopt performance on a core i9-9900 vs. an Apple M1 with two
different C compilers (I posted the clang v12 version). The "No OCR" row compares single-threaded
performance since only the OCR processing in k2pdfopt is multithreaded. The OCR improvement
is not as dramatic, probably because Tesseract has optimizations for the hardware extensions in
x86-64 chips (e.g. SIMD/AVX). Interesting also that clang v12 beats gcc v11 handily. The M1
performance is even more impressive when you consider that its thermal design power (TDP) is
about 20 W compared to the i9-9900's 65 W.
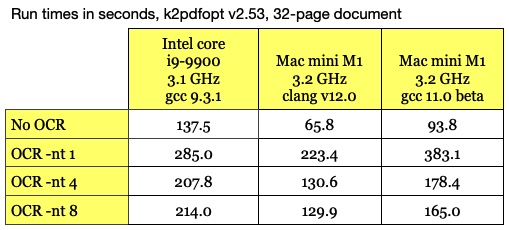
|
| 18 Jul 2020 |
|
K2pdfopt v2.53 released.
This version improves OCR multithreading, adds better DJVU support (text layer extraction),
adds CBZ support, and is compiled with the latest third party libraries, e.g. Tesseract 4.1.1.
See details in the k2pdfopt version history.
|
| 12 Jun 2020 |
|
K2pdfopt v2.52 released.
This is primarily a bug-fix release, fixing over 20 issues that have accumulated over time.
There are also a few enhancements including the ability to directly download Tesseract
OCR language data files (finally).
See details in the k2pdfopt version history.
|
| 9 May 2020 |
|
A new Mac OSX and Linux GUI
called rebook is being developed
for k2pdfopt by Pu Wang.
It is written in Python and Tcl/Tk.
Wang's goal is to mimic the Windows GUI as closely as possible. While adding rebook
to my third-party contribution page, I took the time to update that page, particularly the section on KOReader, which I had not looked it in a while. It has evolved into a very
polished application for e-ink devices.
|
| 14 Mar 2020 |
|
I'm still here. The amount of time I can afford to work on
k2pdfopt has dwindled, but I still hope to get around to some key bug fixes and updated
builds at some point. In the mean time, I do still answer questions on the
mobileread forum and I just did a long overdue update to the OCR help page.
|
| 3 Aug 2019 |
|
My site (willus.com) now offers SSL/https connectivity.
Apparently this happened without my being notified,
at no charge to me, which is nice. As a result,
today I configured my site (and my backup site willus.org) to
automatically
re-direct http requests to https requests.
Enjoy the added security!
|
| 5 Jan 2019 |
|
K2pdfopt v2.51a for MS Windows released. Fixes a bug displaying
PDF file information in the MS Windows GUI. The download page now shows v2.51a.
The MS Windows binaries will show v2.51a, but the Linux and OSX binaries will show v2.51
since they are not affected by the bug.
See details in the k2pdfopt version history.
|
| 4 Jan 2019 |
|
K2pdfopt v2.51 released.
This fixes an issue in v2.50 where the Tesseract OCR would not run on modern PCs and enhances
the accuracy of the Tesseract v4.0.0 OCR.
See details in the k2pdfopt version history.
|
|
|
[... more news] |
ABOUT K2PDFOPT (MORE DETAIL)
K2pdfopt (Kindle 2 PDF Optimizer) is a stand-alone program which optimizes
the format of PDF (or DJVU) files
for viewing on small (e.g. 6-inch) mobile reader and smartphone screens such as the
Kindle's. The output from k2pdfopt is a new
(optimized) PDF file.
K2pdfopt is meant for text-based files on a white background which may also have
graphics or figures, and it works equally well on native and/or scanned or bitmapped PDF or DJVU
files. It is fully automated and can batch-process PDF/DJVU files.
K2pdfopt works by converting each page of the PDF/DJVU file to a bitmap and then
scanning the bitmap for viewable areas (rectangular regions) and cutting and cropping
these regions and assembling them
into multiple smaller pages without excess margins so that the viewing region is maximized.
Making use of this method, k2pdfopt can re-flow text lines, even on scanned documents
(see the Winnie the Pooh example below).
You can see another example of how k2pdfopt works on
this help page.
As of v1.50, k2pdfopt will also embed OCR text
into the PDF so that text can be searched and highlighted, and v1.60 can create
output files with the native PDF instructions from the source file
(if the source file is PDF).
Any kind of PDF/DJVU file (best if it has a primarily white background) can be converted.
K2pdfopt works especially well on two-column or multi-column PDF/DJVU files such as
IEEE and other technical journal articles (see examples below--it auto-detects two-column
regions on the page), but even single-column files will
often be significantly improved and much easier to read (see examples).
K2pdfopt has the advantage over other PDF converters in that it fully preserves
the rendered PDF fonts and graphics from the original file, unlike programs
that convert the PDF to an e-book format. Also, because k2pdfopt is completely independent
of language or fonts, it will work equally well on documents in any language.
HOW TO USE K2PDFOPT
 |
|
No install is required and no extra files or packages are necessary to run k2pdfopt
(Mac/Linux users please see the mac install notes or linux install notes).
Just drag and drop your PDF/DJVU file icon onto the k2pdfopt icon to convert it. You will be
prompted for conversion options (as of v1.16). Click Convert All Files (MS Windows GUI)
or Press <Enter> to convert the file using the default settings.
A new PDF file with _k2opt at the
end of the name will be created. The output file
is optimized for viewing on Kindles
and other mobile readers with 6-inch screens (if the settings are not customized).
You can also drop a folder full of PDF/DJVU files onto the k2pdfopt icon to batch
process them. You can even drop a folder full of bitmap images to have them converted into a
single PDF as if they were pages of a PDF file (page ordering will be alphabetical by
file name).
|
See my k2pdfopt help page for more detailed help.
Note that some older e-readers (e.g. the first-gen kindle) cannot read PDF files.
If you have a Kindle 2, it must have the latest firmware that allows it to
view native PDF files.
MORE EXAMPLES (click on images to get PDF file)
| Example Type |
Original
File |
Default Conversion
optimized for 6-inch
screen at 167 dpi |
Smartphone Conversion
(-odpi 250)
optimized for 4-inch
screen at 250 dpi |
| Text re-flow |
 |
 |
 |
Text re-flow on
scanned pages |
 |
 |
 |
Four-column
(must use -col 4) |
 |
 |
 |
K2PDFOPT GOOGLE SEARCHES
• REVIEWS
• BLOGS
• FORUMS
• TWITTER (#k2pdfopt)
OTHER PDF/CONVERTING SOFTWARE
See my page on PDF Conversion Tips.
RECOMMENDED WINDOWS PDF/E-BOOK READER: SUMATRA
This is my plug for Krzysztof Kowalczyk's
Sumatra PDF reader: a small, efficient, yet feature-rich open-source PDF reader that does everything I want.
Sumatra also displays several file types other than PDF,
including XPS, DJVU, CBZ, CBR, and PS/EPS (PS/EPS requires Ghostscript), EPUB, and MOBI.
It is a refreshing alternative to Adobe's bloatware. I highly recommend it.
|